
Data Quality and Quantity – How to Get the Best of Both Worlds, Part 3 – Results Should Not Confuse You
Editor’s Note: Special thanks to the contributions by Nir Netanel, Technical Leader at Cellebrite.
Digital investigations are time-consuming, so the tools we use should make us more efficient, not more confused.
When you are examining an artifact presented by your tool, you should be able to follow a clear path. That path should tell you the source of the information, let you navigate to the file within the file system or hex, and provide methods for validating the results. Above all, that path should be clear. If you’re finding that this isn’t the case, it’s time to find out why. The goal is to make your investigation road smooth, not convoluted and rocky.
From my first day as a forensic examiner, my boss taught me to ask “why.” Why is the evidence not making sense? Why does one tool produce keywords that aren’t produced by another tool? How did the data get onto the device in the first place? Which artifact does the attachment belong to? You get the point. This concept of always wanting to discover the “why” and the “how” during investigations was ingrained in me early on and I believe it is what has made me a stronger examiner.
Here are some things to consider if you are confused by the results you’re seeing:
- Is your tool interpreting the data correctly?
- Is there more that the tool simply isn’t doing or has missed?
- What are the chances of “false positives?”
- How can this impact your investigation?
At Cellebrite, we understand the challenges you face. Here’s how we’re attempting to mitigate confusion by reducing false positives:
- Cellebrite Physical Analyzer’s (PA) research team invested time to develop the application parsers with an internal logic to remove false positives.
- Junk results are eliminated.
- Duplicates are reduced to show one result.
- When carving for data, PA background activity is running to filter false positives.
- PA provides results in data models that are processed and filtered to drastically reduce the amount of false-positive results.
Get it Right, So I Can Do My Job
Passwords, usernames, and decoded userIDs are important in investigations. Examiners need usernames and userIDs to associate people with communications and login activity. Let’s be honest, humans are creatures of habit and passwords are often reused. This is helpful to know when you’re trying to unlock a device or decrypt a container.
If we uncover passwords and usernames from a device belonging to a user of interest, chances are good that we can recover a password that may be leveraged to access an inaccessible device or cloud data (assuming you have the rights to access that data).
Below is an example of usernames and passwords recovered from Chrome. Browser data is a fantastic place to reveal usernames and passwords to websites, applications, and more.
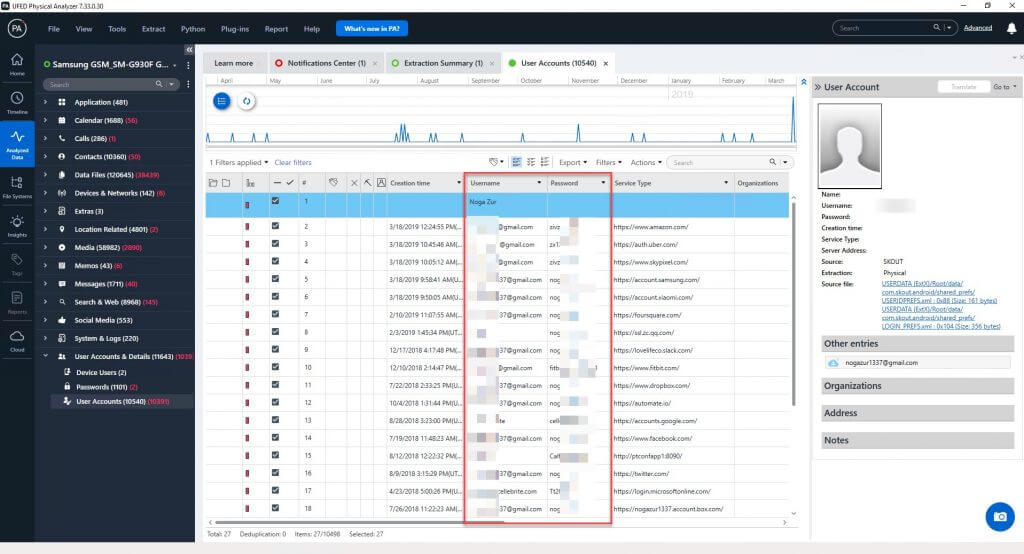 In the instance that PA cannot decode the password, the “type” of passcode is provided so that you have a better understanding of why (cert, key, token, etc.).
In the instance that PA cannot decode the password, the “type” of passcode is provided so that you have a better understanding of why (cert, key, token, etc.).
As shown below, you can see that the passcode was not recovered and that the type is a key. Also note that the identified duplicates are not shown to you unless you select for those to be included. This is a way to save you from having to sort through multiple files and then chase down the reason why you cannot parse the password.
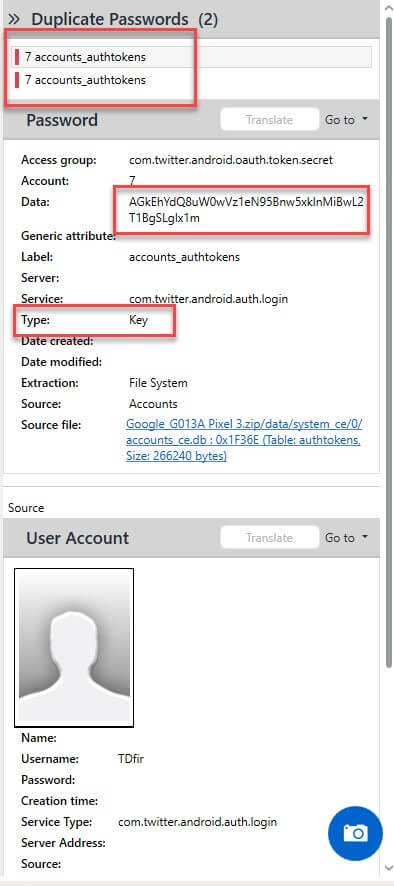 However, in the instances where you need to verify or ensure the password was decoded correctly, you can easily do so. Below I am verifying that this information is correct. You can see that I filtered the database for the “Data” of interest.
However, in the instances where you need to verify or ensure the password was decoded correctly, you can easily do so. Below I am verifying that this information is correct. You can see that I filtered the database for the “Data” of interest.
 If you want to dig even deeper, you can leverage the “SQLite Wizard” to draft a query or use the features built in to guide you to the results our developers have built in for you. Again, I believe in verification, so let’s do it.
If you want to dig even deeper, you can leverage the “SQLite Wizard” to draft a query or use the features built in to guide you to the results our developers have built in for you. Again, I believe in verification, so let’s do it.
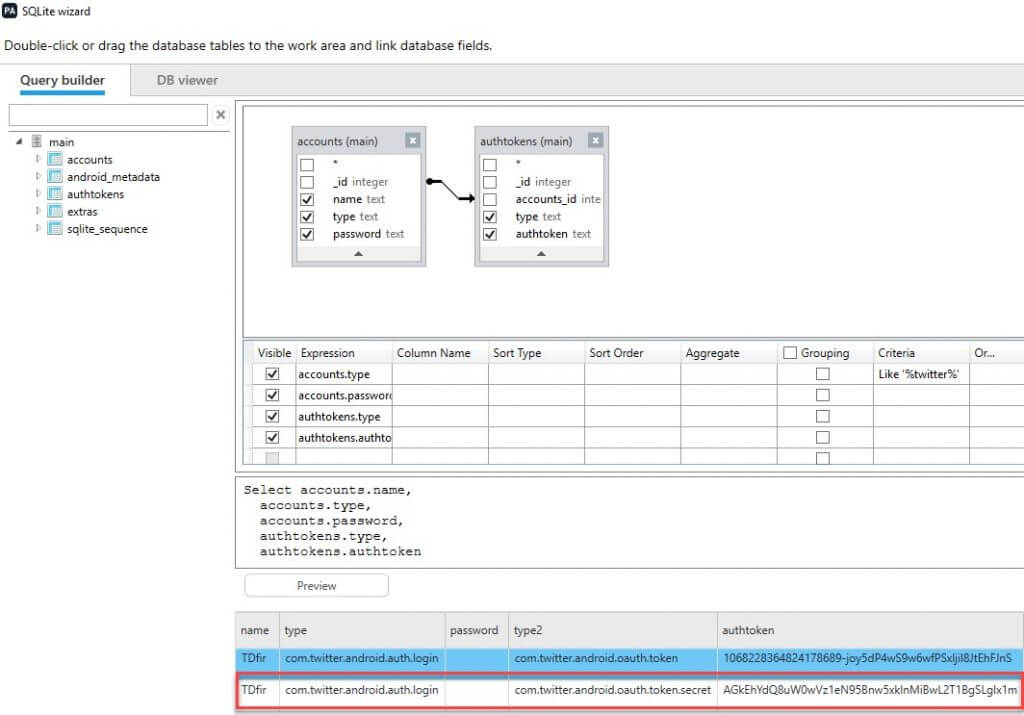
Here is the query I wrote for this specific example, which is from Josh Hickman’s Android Image1.
SELECT
accounts.name,
accounts.type,
accounts.password,
authtokens.type,
authtokens.authtoken
from accounts
left join authtokens on authtokens.accounts_id=accounts._id
where accounts.type like ‘%twitter%’
Here are the results in the SQLite Wizard. This is a great way to validate findings within your tool. You can export the database and validate in another tool with the query listed above.
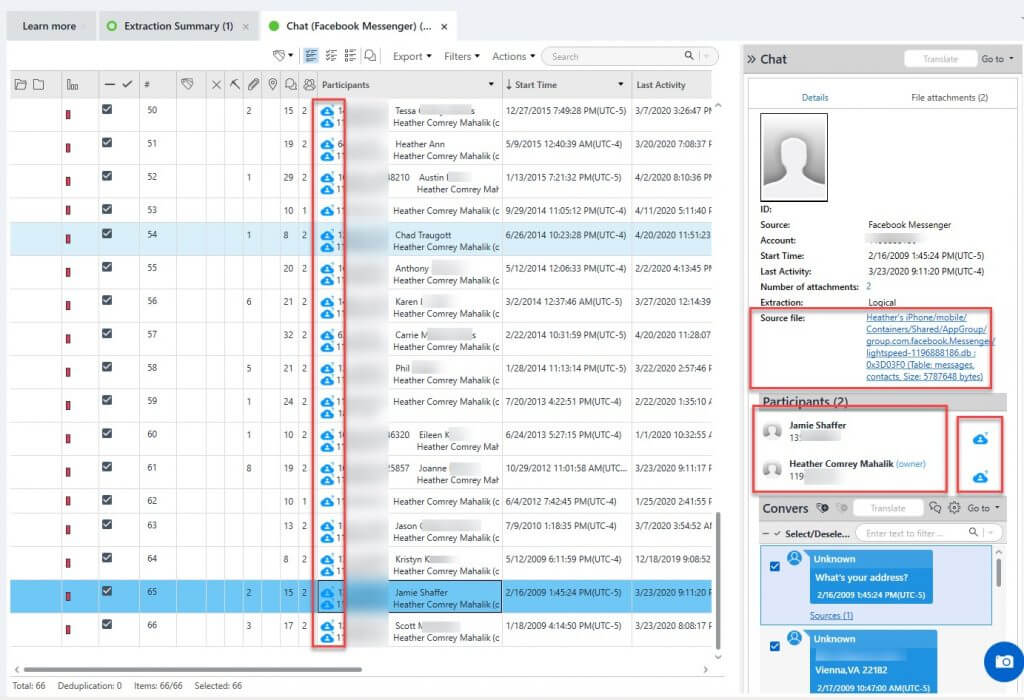
Finally, usernames and userIDs are examined. In the example below I am showing my personal Facebook Messenger (hence the blurring) to show you several items of interest and how good a job PA does in parsing the data. Note the usernames associated with the Facebook IDs.
Not all tools provide this amount of clarity, which means you need to follow the source and follow the steps that I showed above to write a query and join the tables. The dark blue clouds are public cloud information. When the cloud is a darker blue, it is considered “high confidence.”
 From my testing, public cloud that is “high confidence” has been correct, but don’t trust my findings. Validate it if it matters in your investigation. Follow the source and examine the database or the Hex.
From my testing, public cloud that is “high confidence” has been correct, but don’t trust my findings. Validate it if it matters in your investigation. Follow the source and examine the database or the Hex.
Now that we have a better understanding of accounts, userIDs, and passwords within PA, let’s dive a bit deeper into the data.
Wait, Where Did You Come From?
When considering attachments, you really need to know the source. If you cannot easily link the attachment to the message, it may end up being overlooked or it may not add as much impact.
Years ago, I worked an investigation that involved a chat messenger and attached photos. If you read the chat without the graphics, it didn’t seem related to the investigation as the suspect was careful with his wording. However, once the attached photos were included, it solved what we were looking for. This case involved a minor, so enough said there, right?
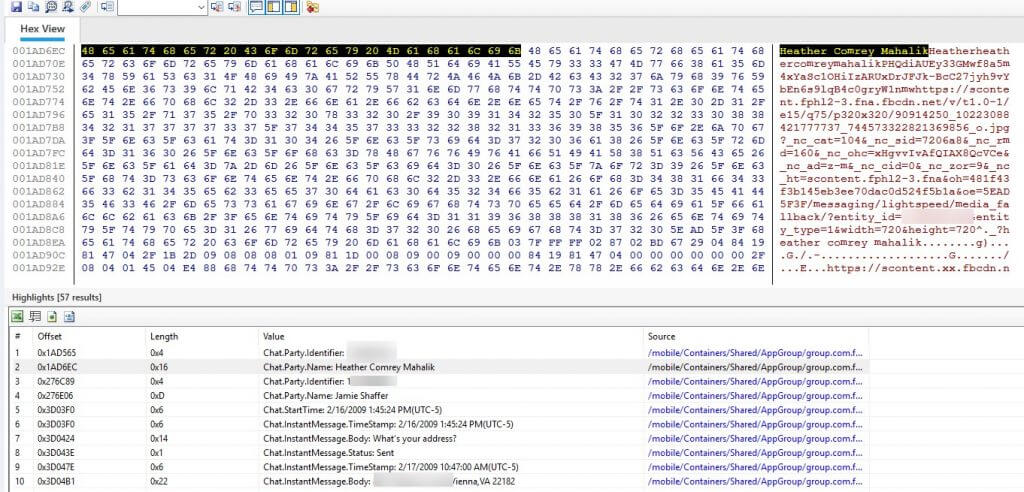
Let’s look at some examples of how PA keeps everything together in a nice little packaged data model for you. Below we see an e-mail message with an attachment. Note how everything is organized in the right pane for you. Key components of the e-mail (sender, subject, date, folder, etc.), the source, the body, and the attachments are also included. Also take note of the light blue cloud. This would mean the information is “low confidence” even though it is correct.
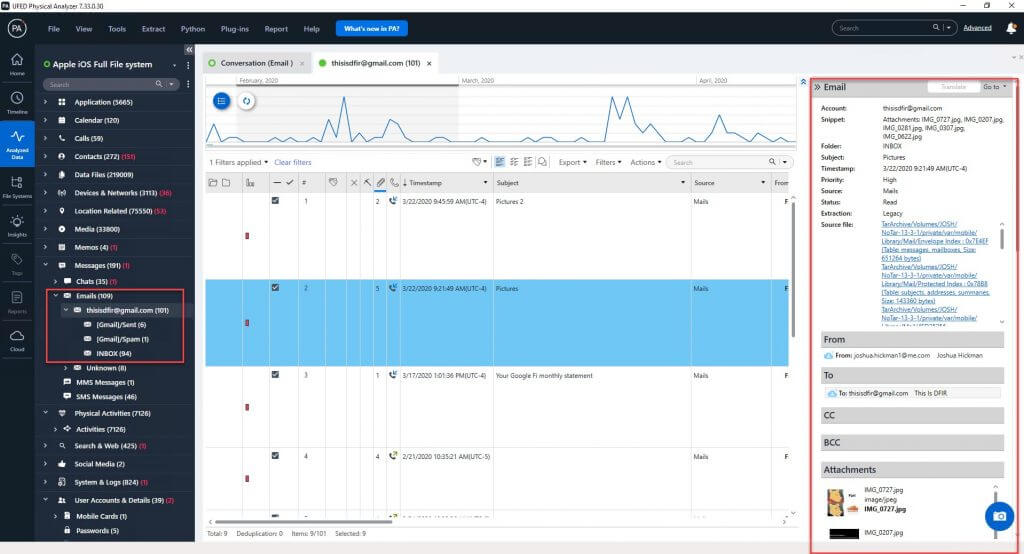 What if you have a duplicate message with attachments? The duplicates are noted at the top-right corner of the pane (below). As you click on each one, the source will change, so you’ll know where it’s coming from. Also, take note of the number under the “paperclip” column as that indicates the number of attachments. You need to make sure you know how many attachments were attached to a specific message.
What if you have a duplicate message with attachments? The duplicates are noted at the top-right corner of the pane (below). As you click on each one, the source will change, so you’ll know where it’s coming from. Also, take note of the number under the “paperclip” column as that indicates the number of attachments. You need to make sure you know how many attachments were attached to a specific message.
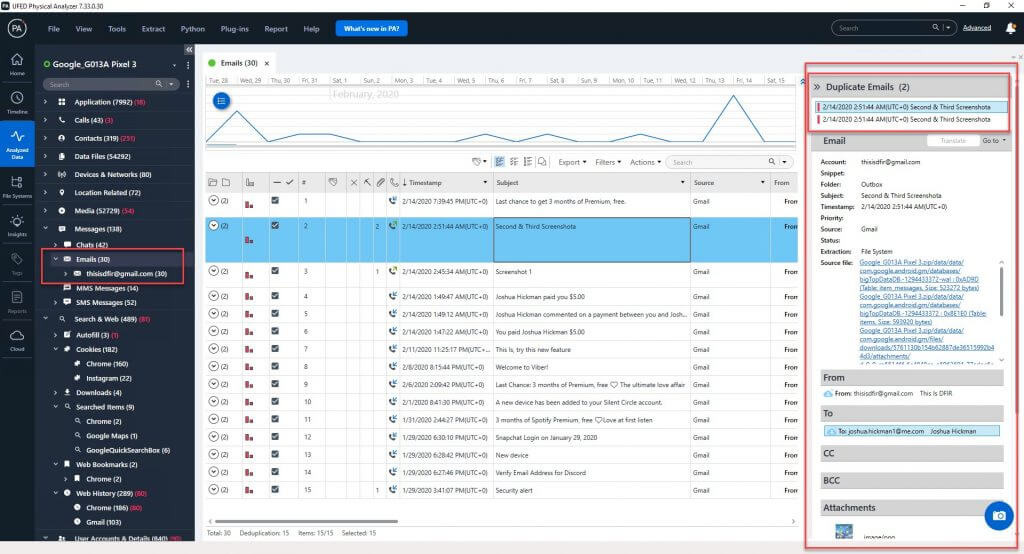 Trust me, trying to make sense of attachments and messages is not easy if it’s not done for you. A timeline will help, but it’s still time-consuming and can be difficult if you don’t have links associating the data to the proper message. Let’s now look at Telegram as a third-party application example.
Trust me, trying to make sense of attachments and messages is not easy if it’s not done for you. A timeline will help, but it’s still time-consuming and can be difficult if you don’t have links associating the data to the proper message. Let’s now look at Telegram as a third-party application example.
In example below we can see a Telegram conversation with multiple attachments going back and forth. The Source files are highlighted, and the red arrow shows that there are three of these. This means you get to manually query and join three tables like I did at the beginning of this blog.
In my opinion, your tool should get you started, and you should only need to go to the hex and databases to verify. Again, piecing something like this together manually is going to require a solid query and a script to pull the attachments in. PA is designed to handle these attachments and piece the puzzle together.
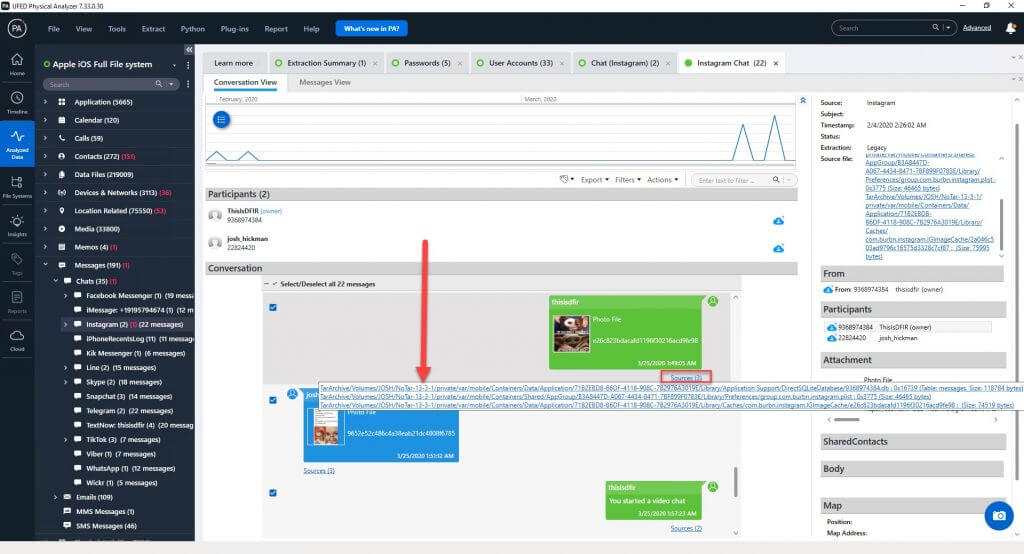
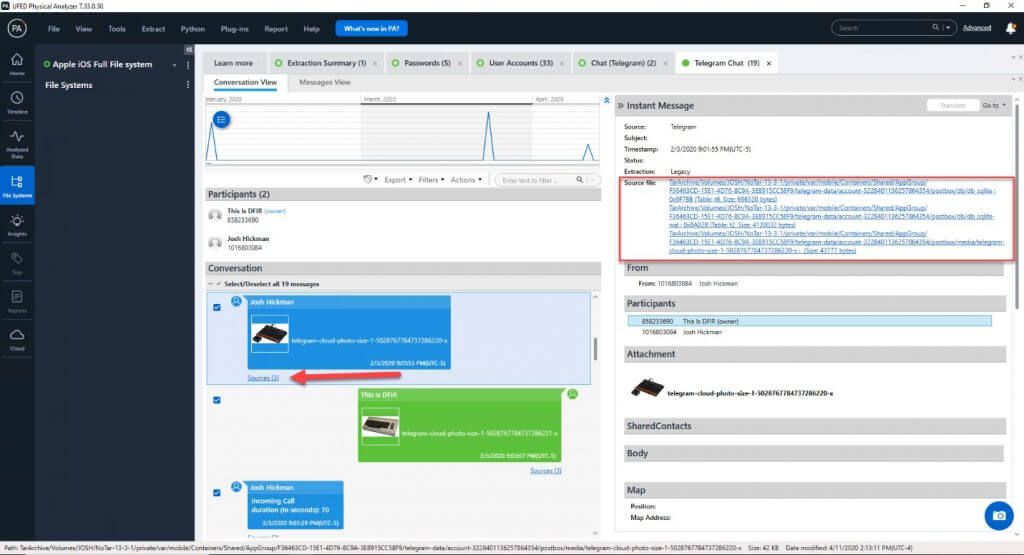 Below is another example where Instagram is the source. Note how you can click on the three sources here and see the files as shown by the red arrow. If you click on these links, they will take you to the source file within the file system.
Below is another example where Instagram is the source. Note how you can click on the three sources here and see the files as shown by the red arrow. If you click on these links, they will take you to the source file within the file system.
 Too Many or Too Little – The Impact of False Positives
Too Many or Too Little – The Impact of False Positives
Now that we have discussed the good things, what about bad things like false positives? I am a believer in the ability to collect everything and then tear through it. I would rather get more information than not enough, but to a limit.
We don’t have time to dig through troves of false positives and we hope that these results are not co-mingled with our parsed data. In PA, we strive to keep false positives out of the data models (parsed data) as much as possible. However, no tool is perfect. So how to do these false positives get introduced into PA? It’s simple. They come from you! ?
When we carve for additional artifacts, chances are higher for false positives, but that makes sense and is acceptable to me. I am asking the tool to dig for additional things it didn’t parse and filter. So, you may get a lot of false positives. However, this data should be kept separate from the parsed artifacts and put into its own data models (App Genie, Fuzzy Models, etc.)
You can always sort by the carved column as well. It’s really up to you, but you will find that it’s easier to keep information that’s “done by the tool” separate from that which “I chose to carve.” What you don’t want is to have data that is all thrown together because you may not be able to make sense of it. That is frustrating and often turns examiners away. When data is mixed with false positives, it’s easy to miss valuable data because it is being consumed by surrounding junk (false positives).
Let’s look at other ways you may find false positives – suggestions or recommended friends on social media. This can be a nightmare if you think about it.
Let’s say you are working a stalking investigation and the suspect claims they have had zero contact with the accuser. However, you use a tool to parse the suspect’s phone and you find that they are friends on Twitter, Snapchat, etc. The person appears to be lying. However, you then parse the phone in PA and you find that the person is not friends (following) that person, but they were simply “recommended” by the application (i.e. in Twitter “because you follow”).
This can matter and may make a difference in your investigation. I have seen many apps where cached data or suggestions appear in the data, so the tool must be savvy enough to determine if a friendship exists and you must be willing to validate when it doesn’t.
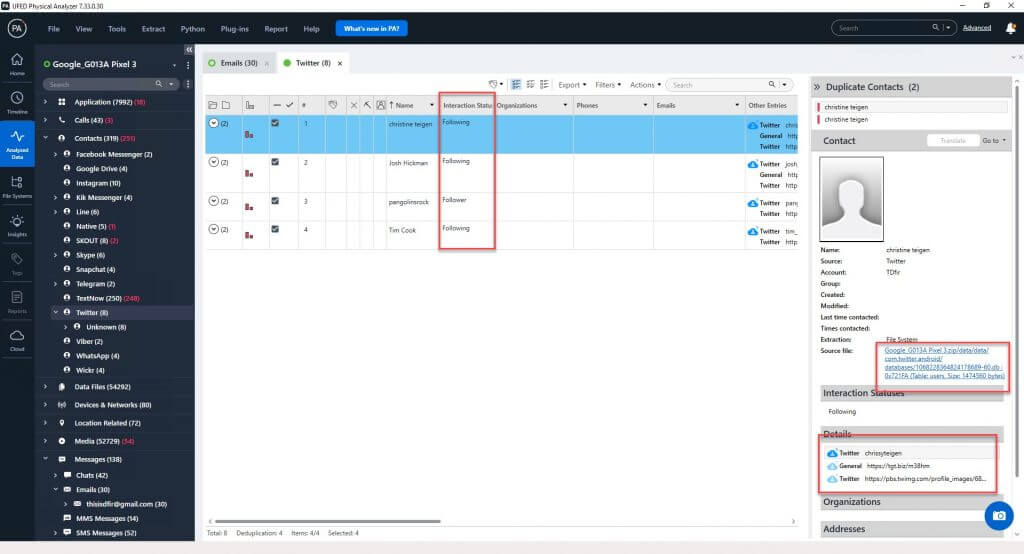
As stated previously, follow the source and verify anything with “low confidence” as it is public cloud information.
For graphics, you may have many false positives especially if you have a physical extraction and you carve. However, what if you don’t? What if you have a full-file-system extraction from an iOS device that has a lot of applications with cached graphics?
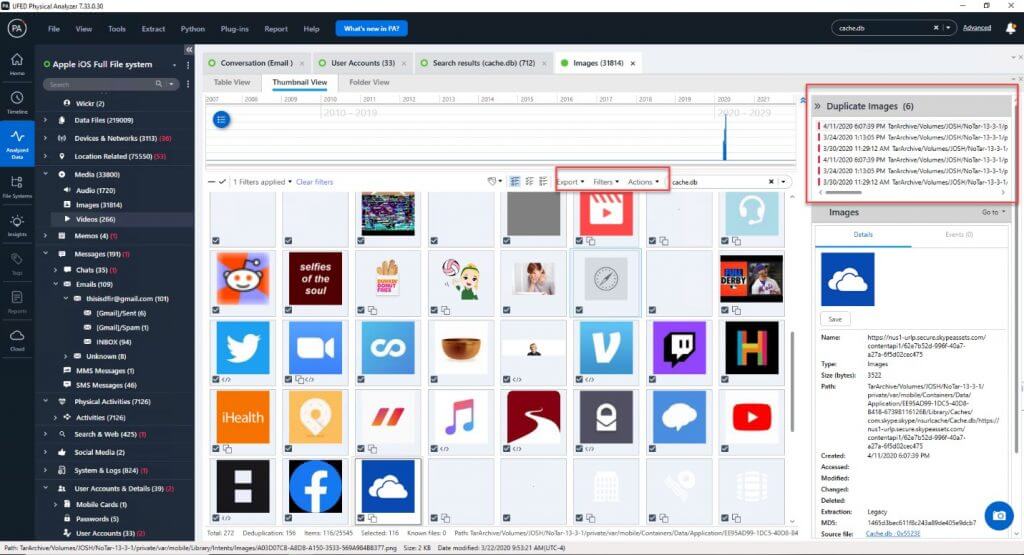
While these aren’t “false positives” they are confusing if you cannot identify where they came from and where the duplicates are. I have spent hours digging through images. Some of the cases we work are harsh and we don’t want to see duplicate images all over the place. Seeing something once should be enough, especially when a tool like PA tells you all the other places the image exists.
Below we can see graphics from Skype cache. Notice that when you click on an image that PA tells you the source for the six duplicates. This is a good thing. Otherwise you may see this graphic six more times during your examination, which wastes your time and may cause confusion.
Have you ever stumbled upon something and wondered, where have I seen that before? I have, too. It can be enough to make you crazy during an examination. Categorization and deduping help so much.
At Cellebrite, our goal is to simplify the examination process. Are we perfect? No. But no tool is perfect. Our goal, however, is to be as close to perfect as possible. We want to make your life easier by showing you data you can trust, but we also want to provide you with methods to easily verify information, if needed.
Our researchers and decoders dig deep to present you with the best data in a clean way. Try what you have seen here for yourself using Josh Hickman’s public images, which are linked below.
If you have additional time-saving features you want to see included in PA, please send them to support [at] cellebrite.com and copy heather [at] cellebrite.com with the subject “Time Saving Features in PA.”
Resources
[1] Josh Hickman’s Android Image – https://thebinaryhick.blog/2020/02/15/android-10-image-now-available/
[2] Josh Hickman’s iOS Advanced Logical and Checkm8 Extractions – https://drive.google.com/file/d/1GQP_y1340LHcq8eiDOYKAma62Q8GEyN5/view?usp=sharing
