
How AI and Machine Learning Are Impacting Digital Investigations
Digital investigations today frequently involve the timely access to increasing amounts of photo and video data. With the rise of photo sharing apps and the ever-growing storage size in digital devices, it is not uncommon that a digital investigation, involving even a few devices, may contain hundreds of thousands, of photos as well as hundreds of hours of video footage.
Investigators need to be able to leverage this data quickly to help resolve an investigation.
Technologies for video and image analysis have been around for decades. However, with the advent of AI-powered Computer Vision, these technologies are now more powerful and more affordable than ever.
One such technology is Media Categorization. This AI technique can flag potentially important images for investigators including images that may contain drugs, weapons, faces, money, documents, screenshots, maps, illicit images and more.
Think of an investigator running a drug-related case who can now immediately review all of the potential drugs images, while also be alerted about images that contain a stack of cash.
Media categorization is very helpful when the tool used can identify the category in question. But what if investigators need to find images of invoices and receipts (as in cases involving fraud), without there being predefined media category?
In this whitepaper we will explore how recent breakthrough developments in AI and software engineering allow users to teach a machine to recognize a new category in just a few minutes—with as little as a few dozen images.
AI Powered Computer Vision
Artificial Intelligence and Machine Learning
The term artificial intelligence (AI) dates back to as early as 1956. Back then, computer scientists were optimistic as to the possibility of developing a “thinking” machine within a few decades. Today, that thinking capability is a reality, but the terminology can be confusing.
The terms “AI” and “machine learning” are often used interchangeably, however there is a subtle difference between them. AI refers to any use of computers to mimic the cognitive functions of humans. AI may refer to such operations even if the algorithms behind them where hard coded by humans. Machine learning refers to the ability of a computer to learn an optimal algorithm by themselves, based on data that they are given.
Training computers to “think like humans” is achieved in part by using neural networks. Neural networks are a family of algorithms modeled after the human brain. Our brain can recognize patterns and help us categorize and classify information. Neural networks do the same for computers. The brain is constantly trying to make sense of the information it is processing. To do this, it tweaks and changes the connections between neurons in the brain. Neural networks do the same for computers.
“Deep Learning” (also known as “deep neural networks,” which refers to the many layers of ‘neurons’ involved), is one of the latest advents in machine learning.
Deep learning networks need to see large quantities of items in order to be trained. Instead of being pre-programmed with parameters (known as “weights”), the systems learn from exposure to millions of data points
The AI Boom
Recently we’ve seen a rise in neural-network-based machine learning primarily because:
- GPUs have made it affordable
- There is a lot more data available
- Focus in academic research has increased
- It is powering major industries such autonomous driving, customer support, etc.
Media Categorization Using Deep Neural Networks
In 2012 , Alex Krizhevsky , a PHD student from the University of Toronto, amazed the computer-vision world by presenting a work that improved the state-of-the-art result on the ImageNet challenge dramatically. This challenge involved training a machine with about one million tagged images of real-life objects and concepts, and then trying to predict the concepts and objects in non-tagged images.
Krizhevsky used a Convolutional Deep Neural Network. This is basically a neural network made out of several layers of neurons, where the functions that transfer information from layer to layer look like basic manipulations of pixels.
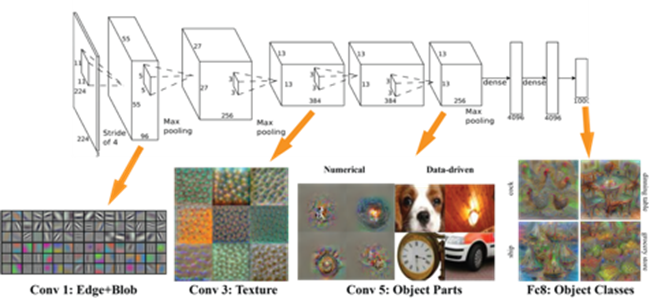
1. Convolutional Neural Network image from:
https://www.cc.gatech.edu/~hays/compvision/proj6/
This network architecture was dubbed “AlexNet,” and started an era of ever-improving neural networking technology and architectures that today, given enough computing power, perform close or even better than humans
Challenges in New Category Model Training
Training a Complete Neural Network is Expensive
The naïve way of a adding a new category to a generic, multi-class image-classification model involves adding at least a few hundred and possibly thousands of images of that category to the dataset, which was used to train the original model. By doing so, a full training of the network should take place – which may take a few days to complete on a high-end GPU. This makes running several iterations of the model training process very expensive.
Luckily, a simpler method exists, which delivers satisfactory results. It is called “Transfer Learning” and it involves just training the last few layers in the neural network; not the entire network. The idea behind this method is that normally, the first layers in the neural network “learn” very generic concepts about light, color and shapes. The output of these layers is then used to identify higher-level visual concepts like objects or scenes.
Dataset Retagging
Using transfer learning to train your custom model in several categories can be very effective for a small number of categories. When you model grows, and the dataset that is used for training grows with it, adding a new category becomes harder and harder because it is necessary, with every new category added, to retag the entire dataset because other images in the dataset, incidentally, could also match the new category. One possible solution is to use transfer learning multiple times—once per category to create a set of Binary Models, each of which is capable of matching a single category. This way may be easier to train, but it will be slower when used for inference as it requires running all of the models in order to match all of the categories.
Data Ambiguity
Some data categories can be tricky to train as even people may not agree on the proper category of an object or a scene. For example, when creating a category for weapons, some people might tag a squirt-gun as a weapon, while others might consider it a toy and refrain from tagging it as weapon. As a consequence, tagging of new data needs to be done by more than one person, so that the model can learn only from data upon which there is a broad agreement between human taggers. This technique is called “Cross Validation.”
Case Ad-Hoc Media Classification
Image Embeddings to the Rescue
One of the interesting aspects of using neural networks is to try and understand what happens inside them. It turns out that as the information progresses through the different layers of the network, the layers are being activated by lower-level concepts in the first layers (light/shadow, edges) and higher-level concepts in the layers after that (specific shapes, corners, objects). It is noteworthy to mention that the neural network organizes itself in this way through its self-learning process.
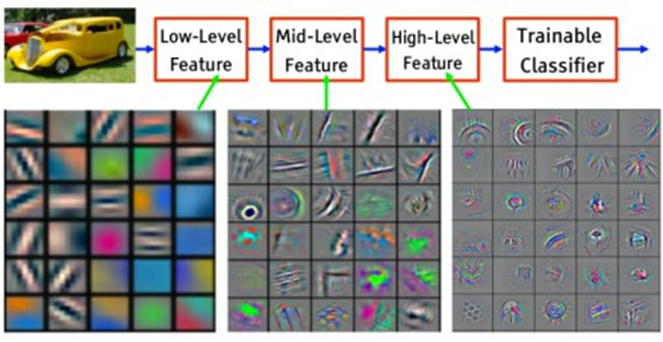
The trick is in exploiting a by-product of the self-organizing network for something it wasn’t intended to do in the first place. The network is trained to classify images into categories but by using the data from one of the neuron-layers as a representation for what’s in the image, we can create an image similarity feature.
The idea is that if this layer “encodes” or “understands” some visual concepts, then similar images with similar concepts will activate that layer in a similar way.
In that sense, we can look at the neurons of that hidden layer as a set of features. This means that each neuron (or a combination of neurons), may encode the existence of a certain trait of the image. We can think of an activation of a layer with N neurons as a vector in N-dimensional space. This vector is called a “Feature-Vector” or an “Embedding.”
Embeddings are, therefore, dense mathematical representations of content. If two embeddings are similar to one another – chances are the content will be similar as well. For images, this means that if the extracted feature vectors are close to one another (in N-dimensional space), the images they represent are more likely to be similar to one another. Close vectors will normally represent images with the same theme (people eating, forest scenery) and very close vectors may represent near-identical images
This opens a possibility to use the embeddings to quickly categorize and search for images in case data.
Custom Ad-Hoc Media Categories
Data on digital devices is not random. Most people don’t have random images on their phones. They usually contain subsets that pertain to events or themes. A dancer may have a lot of dance images and videos on their device while a hiking- enthusiast may have many images of the outdoors. This means that the number of “concepts” that are represented on an individual device is relatively much smaller when compared to the total amount of all the possible concepts in the world. As a result, if we want to classify or “teach” a machine to identify a concept in the context of that specific device (or a set of devices), this may end up being a much simpler machine-learning task than trying to learn that concept in the context of random images.
Enter ad-hoc media categories. Following extensive research in Cellebrite labs, we have shown that it can take only a few dozen images to bootstrap a training process that can teach a machine to discern a specific concept in the context of several million images in a specific case.
Using the embeddings extracted for each image, we help the machine to learn how to tell an image that contains the desired concept from one that does not. Through an iterative process that takes just a few minutes, anyone can train Cellebrite Analytics to identify a new concept in images and find the images that contain this concept.
The process goes like this:
1. Start with an initial set of images that contain the desired concept
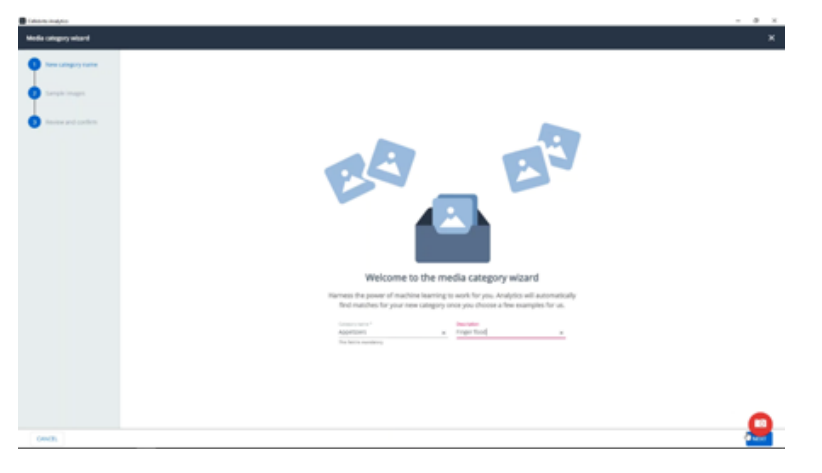
2. Let the system try and find images that are similar in content to the initial set.
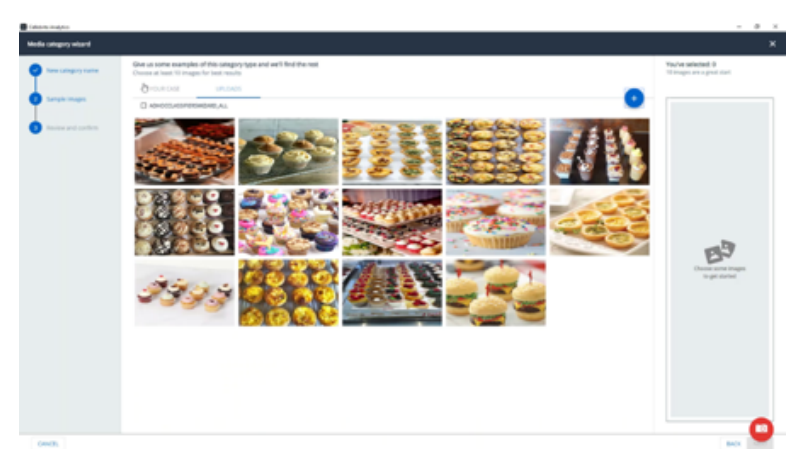
3. Tell the system which of the images it found match the concept and which do not
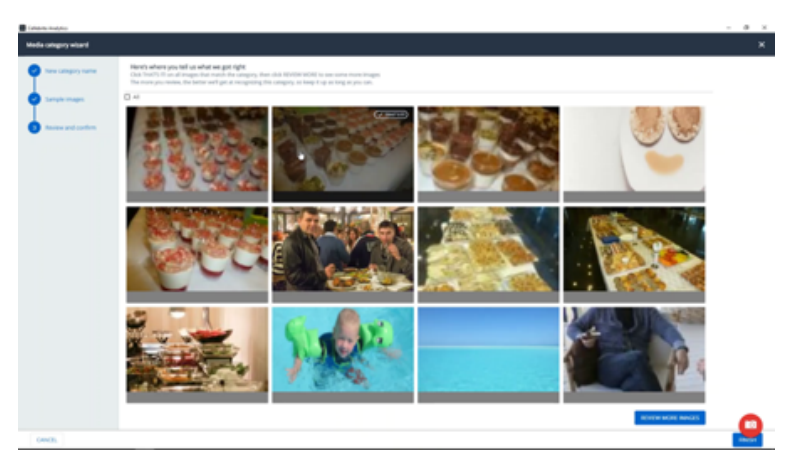
4. The system will adjust its internal model and try to get another set of relevant images.
5. Once again, tell the system which of the images it found match the concept and which do not.
6. Repeat steps 3-5 a few times (this process usually takes only a few minutes).
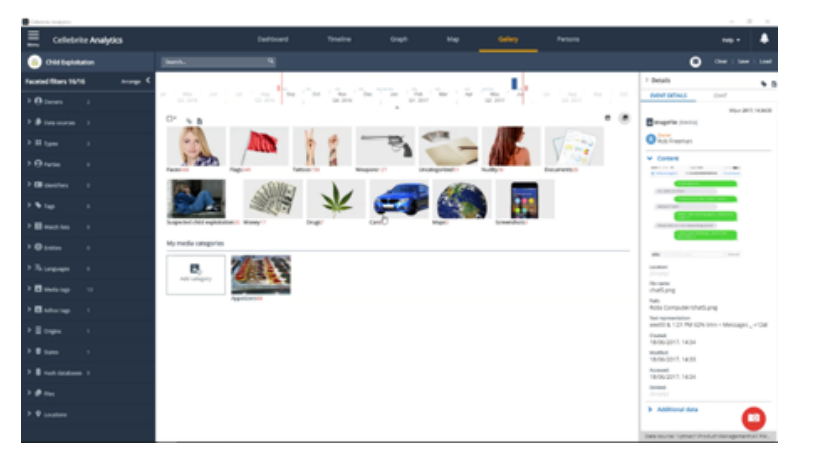
7. When the process is finished a new category will appear in the system.
Why Cellebrite
As the industry leader in digital forensic solutions, we understand the structure of data better than anyone else. This expertise ensures our advanced analytics tools deliver the deepest, most accurate insights possible. Now you can simplify and automate complex analytical tasks, cultivating more leads in less time. Cellebrite’s cutting edge, neural-network- based machine learning algorithms allow you to discover key evidence faster to solve cases more quickly. Features include:
- Industry-First Custom Media Categorization
Cellebrite Analytics now allows users to define their own image category using the process described in this whitepaper. The process takes just a couple of minutes and requires only a few dozen sample images.
- Video Category Synopsis
Save valuable review time by focusing only on the frame or frames of interest within a specific video file. Our ever- expanding neural-network-based machine learning now provides automated image and video categorization of individual video frames for the following predefined categories:
- Drugs
- Faces
- Suspected Child Exploitation
- Weapons
- Documents
- Screenshots
- Money
- Nudity
- Flags
- Maps
- Cars
- Handwritten items
The different categories are clearly marked on the video playback bar, allowing the user to quickly review the different categories within a video file. This allows the user to save time and skip between frames to focus on specific frames of interest.
- Facial Recognition
Cellebrite Analytics automatically detects and surfaces faces within media files to jump-start your investigation. You can quickly and easily search for images containing the same face as in the reviewed image, further surfacing leads and expanding the investigation by making automatic connections between media files based on persons of interest.
- Media Similarity
Going beyond known hashes and searches for previously unknown similar media, users can upload an image or select one from within the digital evidence, and the system searches for similar images in the same way we find images containing a similar face. The similarity is calculated based on a machine-learning model inspired by our own brain structure. With this capability we can “train” the system to understand objects in an image by feeding it many examples, thus allowing the system to “learn” how to identify objects previously unseen by the system.
This capability allows you to search for visually similar images such as suitcases, symbols, rooms, themes or images. For example, in child-exploitation cases where the investigator suspects that while the victims change, the location is the same, they will be able to find additional victims by finding additional photos taken in the same room. In cases where a mug shot of a suspect is available, you can upload the image and search across the entire case data for images containing a face like the one uploaded. This allows you to focus only on relevant media to reduce image-review time.
Clearly, custom media categorization provides a direct pathway for investigators to identify images that may contain drugs, weapons, faces, and other criteria more easily.
When combined with machine learning to create embeddings that can discern specific concepts within the context of millions of images in a specific case, this technology becomes exponentially more powerful, allowing investigators to quickly sort through larger volumes of data in a much shorter time span—greatly improving time to evidence while preventing burnout of law enforcement personnel. And the incredible beauty of it is that teaching machines this iterative process takes only a few minutes once investigators are properly trained.
The benefits can be immediate for investigators as the Cellebrite Industry Trends Survey revealed an excessive amount of time is being spent on the review of data.

More: https://www.linkedin.com/in/orenyosifon
To learn more about how your team can take advantage of this amazing technological breakthrough: Cellebrite.com