
Data Quality and Quantity – How to Get the Best of Both Worlds, Part 1
Do Other Tools Really Parse More Information?
Working a mobile forensic investigation can be time-consuming as data is literally everywhere, device sizes are increasing, and our level of access is growing. Most of us leverage commercial tools to aid in our investigations, which means we need to ensure the tools are showing accurate information and not polluting our investigation with duplicates and nonsensical data.
My question for you, however, is how do you know what you can trust?
For nearly 11 years, I have primarily focused on mobile investigations. I have worked with many tools, (both commercial and open-source), created data sets, developed scripts, provided instruction on mobile forensics, and developed my own methodologies and reasoning for the tools I use.
If you know, me, you know I’m a fan of digging deeper and validating your tools and their parsed artifacts. Why? Because no tool is perfect and because mobile is constantly changing.
This blog series will focus on key areas that you should look at closely. In the series we’ll be answering key questions examiners commonly face including:
- Is another tool really parsing more?
- Does that tool allow you to validate or verify the source of the information?
- Are the other tools enabling you to use your time efficiently?
Time is rarely on our side when it comes to digital investigations. At Cellebrite, we want to make the most of your valuable time.
Dealing with Duplicate Files
When it comes to parsing data, other tools may report more findings, but are they legitimate? Are they simply duplicates? Are the artifacts that exist in several databases or plists, and do they contain the same information?
Seeing the same data repeatedly can drive me crazy! I have stopped during many investigations and asked, “Haven’t I seen this before”? and “Shouldn’t this already be tagged”?
This is maddening. When I work a case, I want the data to be de-duped, accurate, and presented in a format that allows me to dive right into the file system and find the source.
Cellebrite Physical Analyzer (PA) has a unique way of categorizing data in that it not only parses the extraction for artifacts, but it will search the extraction for duplicates from multiple sources. It then places them into one category for easy viewing and simplified analysis.
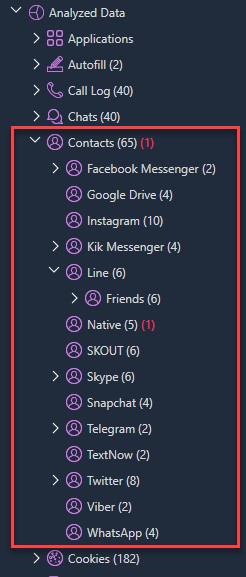
Below, you can see the Contacts as parsed by PA.
For this example (and most shown in this blog), I used the public Android 10 image created and shared by Josh Hickman. This way you can validate and compare them yourself using the same image!
Josh Hickman’s Android 10 Image
Here you can see that when PA is used, the Contacts are listed under one data model. This is very different from other tools that may place artifacts in Chats, Conversations, Social Media, or other places, requiring you to search keywords and tags in hopes of stumbling on what you are looking for.
Why would others not categorize the data in a simplified model? Most likely because the data is not fully evaluated before presenting the data to the examiner; it seems to be simply queried. I have written hundreds of SQL queries over the last five years and know that it’s easier to look at one database and move to the next. However, that leaves you with multiple artifacts that are the same (they are duplicates).
Why would other tools do it this way? The simple answer is that it’s faster and it’s easier for them, but it is not easier for you. It’s the quick approach to running through multiple databases of interest and reporting all findings in multiple locations.
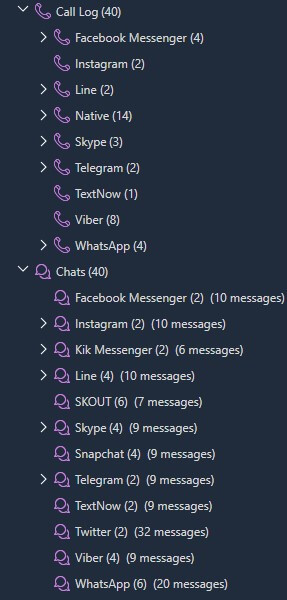
Not only does PA do this with Contacts, we use data models for all mobile devices and categorize artifacts like Chats, Calls, Locations, Web History, and more.
Josh Hickman’s Android 10 Image
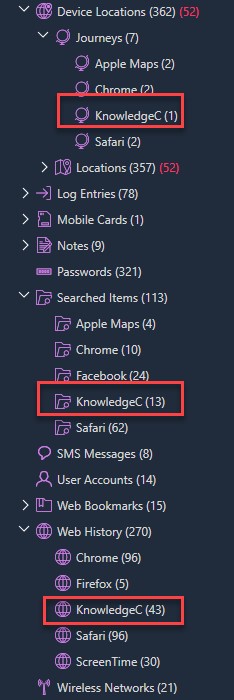
A great example is from a checkm8 extraction shown below. Most are aware that KnowledgeC contains application usage artifacts, but it also contains browser content. Phsycial Analyzer makes this easier for you and places a category for KnowledgeC under every relevant data model and shows only the relevant information for the model.
For example, any application usage artifacts for KnowledgeC would exist in the Application Usage data model where there are unique artifacts for Journeys, Searched Items, and Web History.
checkm8 extraction
When you go to a data model of interest, the results will not be polluted with other items parsed from KnowledgeC. (My special thanks to Sarah Edwards, our BlackBag teammate, for all of her hard work on researching KnowledgeC and for the development of the community tool APOLLO.)
For example, if you are simply looking for application usage artifacts extracted from KnowledgeC, you would simply find just that. You will not find Web History, Google Searches, or Location Journeys. You will find exactly what you are looking for!
PA categorizes the results, making analysis easier. For every artifact we support, PA will merge the same data types while reducing duplicates from multiple data sources.
When it comes to duplicates, you need to be aware that they exist and should have the option to minimize your view of them. It’s frustrating when you search for a keyword in a tool and get 51 hits only to realize that the tool is showing duplicates and there are really just six unique items of interest. This causes confusion for examiners, attorneys, and juries. PA makes this information clear.
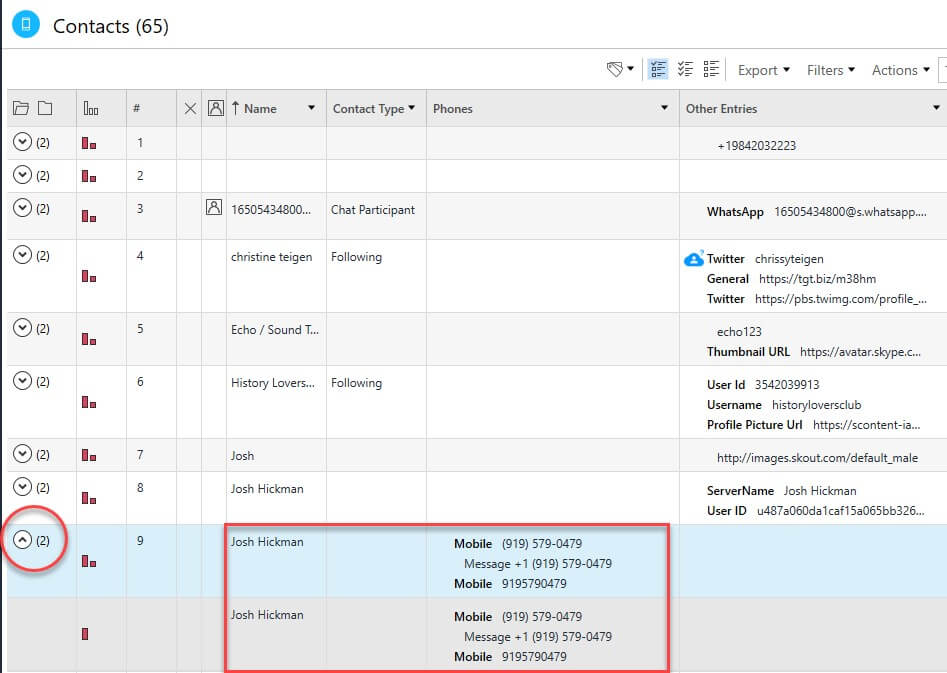
Below we are looking at parsed Contacts. The box that is shown below emphasizes that duplicates exist.
Josh Hickman’s Android 10 Image
We can see that contact information for “Josh Hickman” is showing as a duplicate. If you select the arrow that is circled, you can easily see all of the duplicates that exist. Clicking the arrow again will minimize the view.
I previously stated that a simple view like this is not good enough, which is why PA also shows you the source for the artifact—not only for one artifact, but for every duplicate. We make it easy for you to validate the artifacts of interest. Simply click on the source and you will land in the file system and directly in the file containing the parsed data.
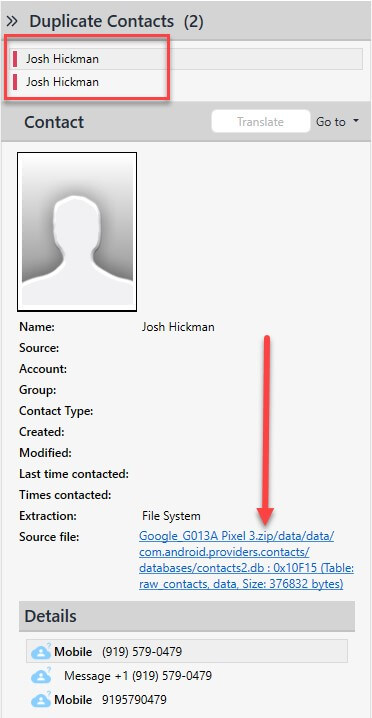

Josh Hickman’s Android 10 Image
Seeing Data Differently
Different views in PA may aid in your investigation as they show the sources in a different manner. Below, we can see WhatsApp Chat artifacts from the Pixel3 device.
This is the “conversation view,” which can be accessed by double-clicking on any conversation. Under each message, you will see a sources button.
If you click on it, the sources will appear, as shown by the arrow below. Three sources contained the exact same message. If we showed you all three, some may think the user typed that message three times, which is not the case.

Josh Hickman’s Android 10 Image
Under every WhatsApp Chat shown in the example above, you will see Sources. This is because we want you to have access to the file that contains the message. These sources may be unique for each message and we have simplified the view for you.
The circle at the bottom message from “ThisisDFIR” is unique to PA. Here you can see the “Platform” icon of a mobile phone representing that the message was sent from a mobile device and not a PC. Also, a “Participants” icon, shows who was involved in that message (person, group, etc.), which may be extremely helpful in an investigation.
Now that I have shown you these examples, I encourage you to download Josh Hickman’s Android Image1 and try it for yourself. You will quickly see that other tools are not deduplicating, categorizing, or placing the artifacts in order to present you with clear findings to make the most of your time.
At Cellebrite, we not only care that you have a tool that works effectively and efficiently, but a tool that enables you to focus on what matters most so you don’t waste precious time.
Resources
[1] Josh Hickman’s Android Image – https://thebinaryhick.blog/2020/02/15/android-10-image-now-available/
